



Article Figures & Data
Figures
- Figure 1. Overview of km.
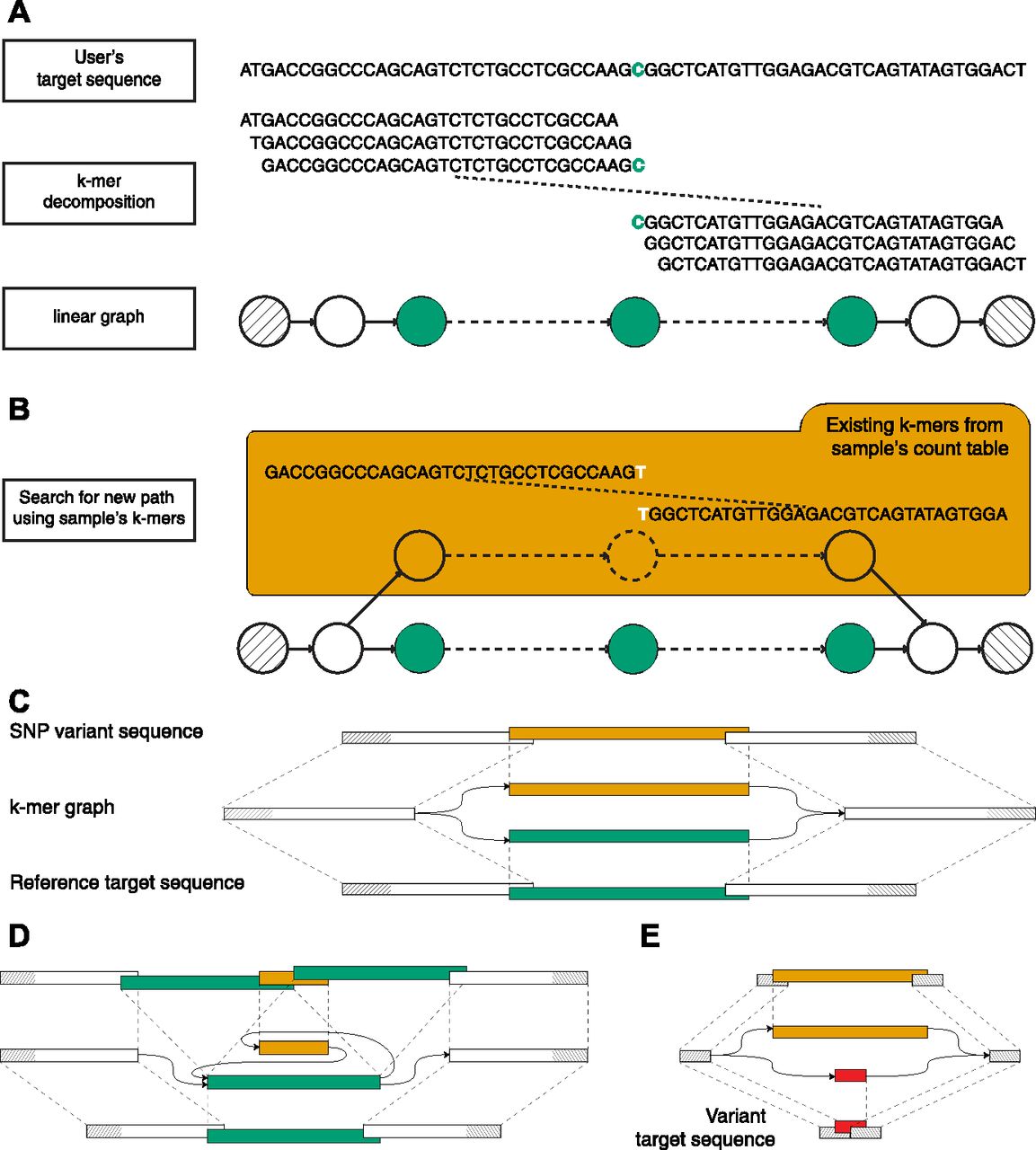
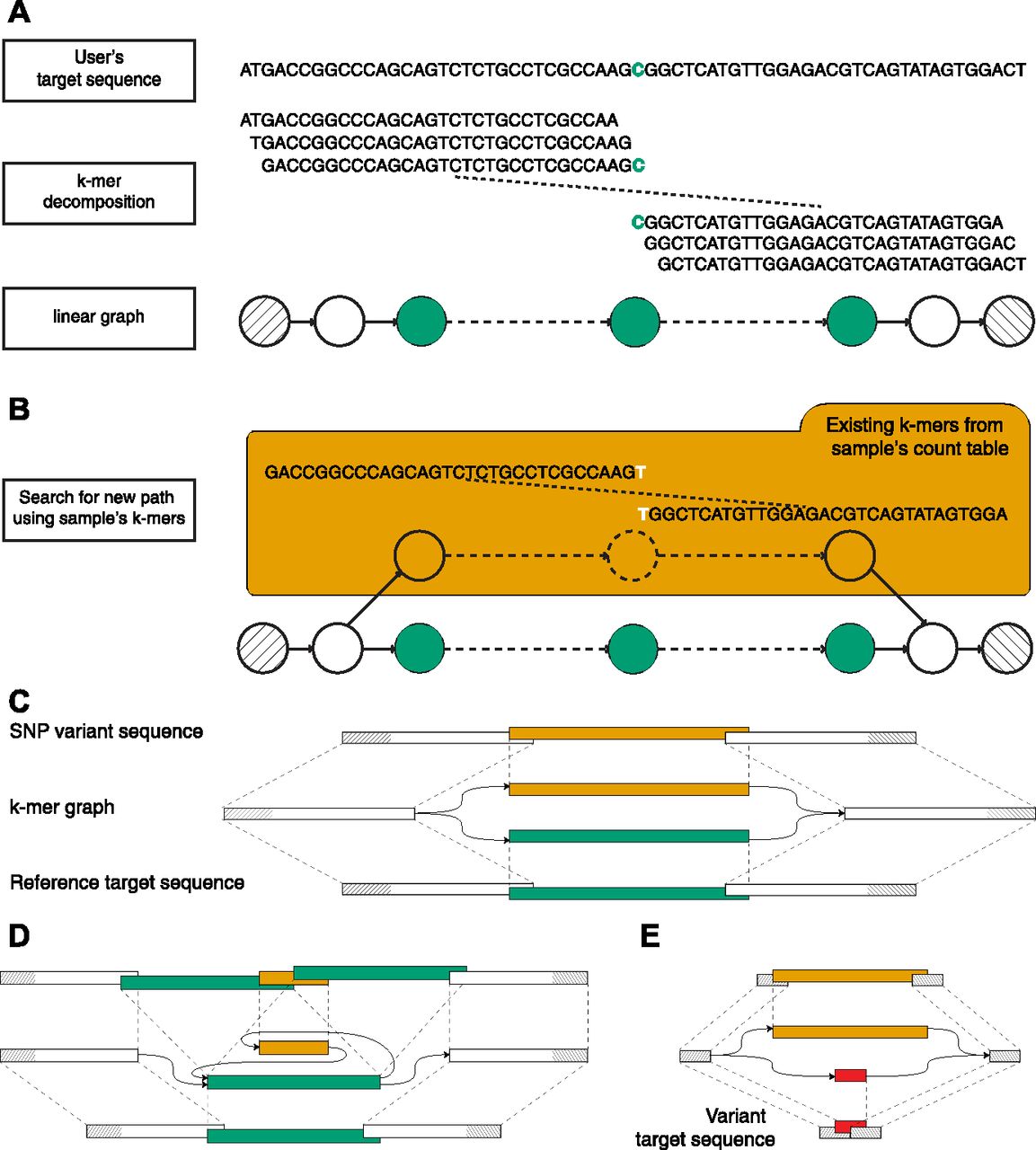
(A) Visual description of how km detects the DNMT3A R882 SNP, using k-mers of 31 bp. The input sequence (target sequence given by user) is centered on DNMT3A’s 882nd codon. This sequence is segmented in k-mers to create a linear graph, which represents the search space delimited by the starting and ending k-mers (hatched). (B) A variant will be represented by a new path between the two extremities. This path is found by walking along the linear directed graph and following new (i.e., not seen in the target sequence) overlapping k-mers, queried from a sample’s count table. (C) Schematic representation of an SNP k-mer graph with each path representing the target (lower) and the variant (upper) sequences. (D) Same representation for an ITD variant. (E) Same representation showing the use of a variant target sequence to initiate km’s search. Here, the expected variant is detected when all k-mers that overlap the starting and ending k-mers (in red) are found in the sample’s count table. Also, additional variants could be detected if another path is found (in orange).
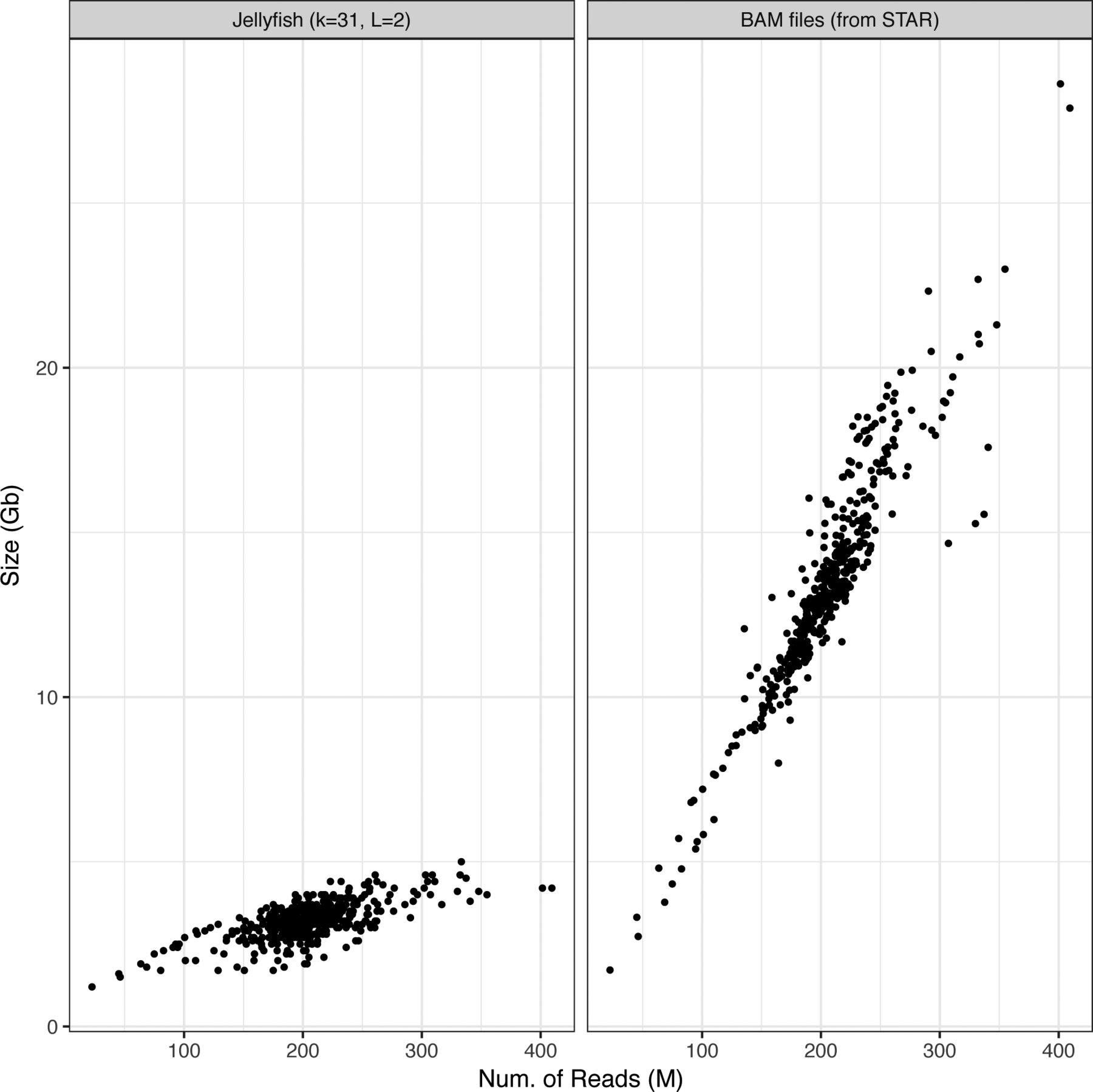
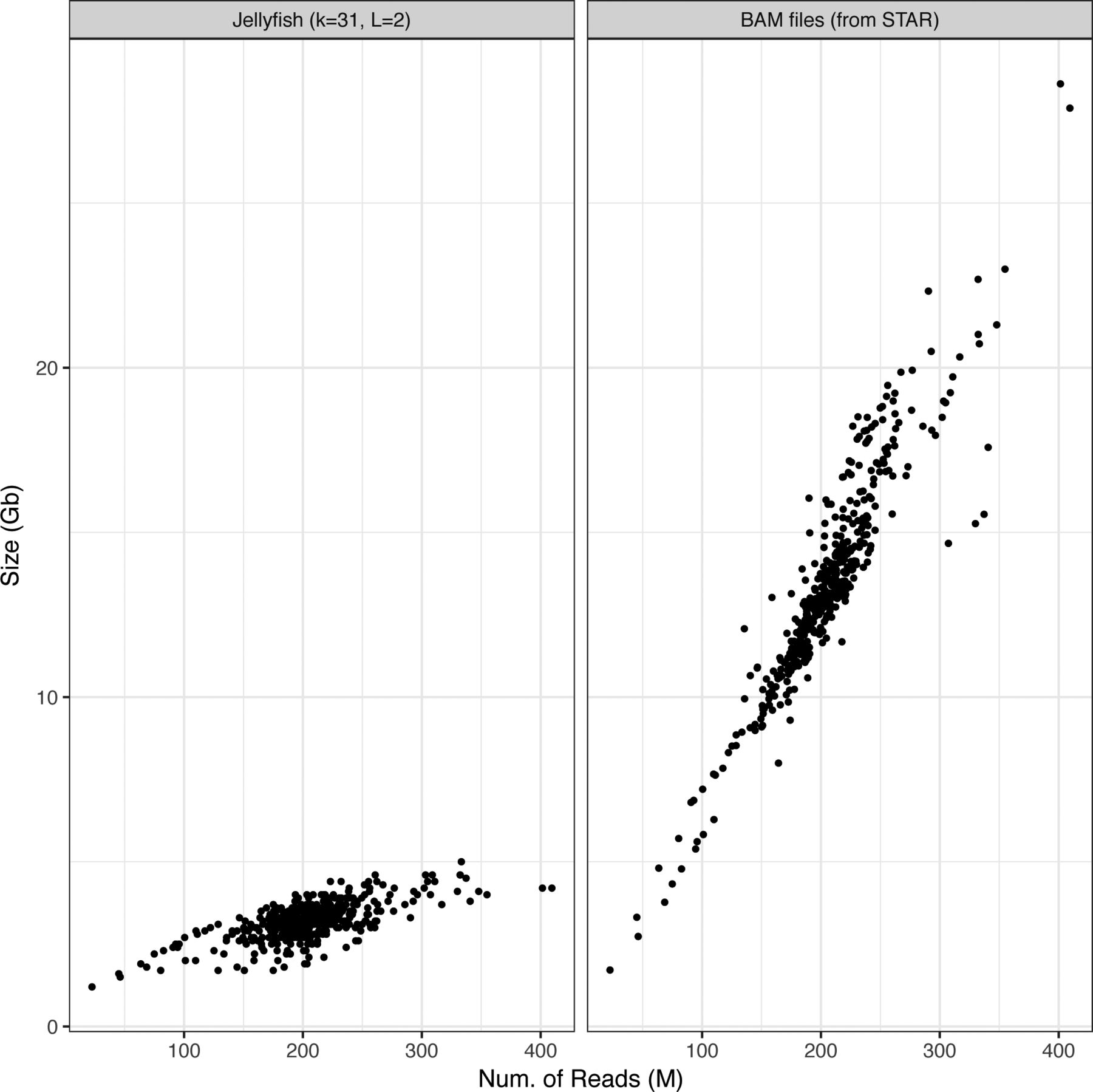
- Figure S1. Comparison of k-mer count tables and BAM files size.
K-mer count tables are created by Jellyfish, with k = 31 bp and minimum k-mer count of 2. BAM files produced following a STAR alignment.
- Figure S2. Percentage of transcriptome sequences from Ensembl annotation (GRCh38.82) that can be represented by a linear directed graph.
At k = 31 bp, 96.76% of the transcriptome can be used as a target sequence. The transcript requiring the largest k to achieve a linear representation is ENST00000621744_NBPF19 and would require k = 3,472 bp.

Tables
Gene Expected type of variant Gene location Target sequence length (bp) Average running timea (s/sample) Reference target IDH1 SNP (R132) Exon 4 65 0.008 DNMT3A SNP (R882) Exon 23 65 0.01 NPM1 4-bp insertion Exon 10–11 + UTR 80 0.017 FLT3 ITD Exon 13–15 345 0.107 FLT3 TKD Exon 20 68 0.019 MYC SNP (T58A/P59R) Exon 2 68 0.018 Variant target NUP98–NSD1 Fusion Exon 11 + 7 62 0.07 NSD1–NUP98 Fusion Exon 6 + 13 62 0.061 KMT2A PTD Exon 8 + 2 62 0.067 ↵a Average computation times are reported for Leucegene samples and assume that k-mer count tables are cached in RAM before running km. The performance of the caching step is highly dependent on I/O architecture, taking around 25 s on a typical system. The approaches used to prepare each target sequence for detecting the expected mutations are presented in the Materials and Methods section.
- Table 2.
Variants identified by km using our AML catalog in the Leucegene and TCGA cohort.
Dataset Mutation name Km type Variant Target Number of samples Ins Del Indel Sub ITD I&I Leucegene IDH1 R132 0 0 0 32 0 0 32 437 437 DNMT3A R882 0 0 0 64 0 0 64 436 NPM1 4-bp ins 22 0 1 0 103 13 139 437 FLT3–ITD 10 3 3 38 83 54 162 429 FLT3–TKD 0 4 0 31 0 0 34 434 MYC T58A/P59R 0 0 0 2 0 0 2 437 NUP98–NSD1 7a 0 0 0 0 0 7 6 NSD1–NUP98 0 0 0 0 0 0 0 2 KMT2A–PTD 10b 0 0 0 0 0 10 15 TCGA (AML) IDH1 R132 0 0 0 11 0 0 11 148 151 DNMT3A R882 0 0 0 12 0 0 12 149 NPM1 4-bp ins 6 0 0 0 28 6 40 151 FLT3–ITD 76 0 5 22 20 18 100 142 FLT3–TKD 0 1 0 11 0 0 12 149 MYC T58A/P59R 0 0 0 2 0 0 2 139 NUP98–NSD1 0 0 0 0 0 0 0 0 NSD1–NUP98 0 0 0 0 0 0 0 2 KMT2A–PTD 3b 0 0 0 0 0 3 0 TCGA (non-AML) IDH1 R132 0 0 0 394 0 0 394 9,850 10,256 DNMT3A R882 0 0 0 0 0 0 0 9,267 NPM1 4-bp ins 0 0 0 0 0 0 0 1,0232 FLT3–ITD 0 0 0 9 0 0 9 163 FLT3–TKD 0 0 0 0 0 0 0 361 MYC T58A/P59R 0 0 0 5 0 0 5 9,204 NUP98–NSD1 0 0 0 0 0 0 0 0 NSD1–NUP98 0 0 0 0 0 0 0 0 KMT2A–PTD 0 0 0 0 0 0 0 0 ↵a Fusion with exon 12 found as an insertion in the target sequence.
↵b Tandem duplication extended with exon 9 or 9 and 10.
Each dataset is split into two parts: reference target and variant target (italic). The “target” column reports the number of samples expressing the target sequence. The “variant” column shows the number of samples where at least one variant of the target sequence is found. As a variant target sequence represents a mutated sequence (Fig 1E), mutated samples counts are indicated in bold. The columns in “km type” identify the specific types of variants detected. Of note, several types of variants can be identified in a given sample. As expected, SNVs on IDH1 are found in AML and non-AML samples on lower grade glioma (LGG) (see Table S1).
Type COSMIC ID Km variant Km type Leucegne TCGA AML A COSM17559 TCTG ITD 103 28 D COSM17573 CCTG I&I 11 4 B COSM17571 CATG Insertion 10 4 COSM20809 CCAG Insertion 3 0 COSM29814 CAGA Insertion 2 0 COSM3356078 CAAG Insertion 1 0 COSM29814 CCGA Insertion 1 0 COSM3356078 CGCG Insertion 1 1 COSM28066 CGGA Insertion 1 0 COSM20811 CTTG Insertion 1 0 COSM20815 TATG I&I 1 2 COSM20813 TCGG I&I 1 0 COSM27390 TTCG Insertion 1 0 COSM20850 AGAA Insertion 1 0 COSM20810 TTGT Insertion 0 1 Unknown gc/CAGGG Indel 1 0 Total mutated/total 138/437 40/151




{kind=link}
{kind=link}
{kind=link}
